
Sometimes I see queries that use SUBSTRING in the query predicate. This makes the query non-sargable (i.e. indexes aren’t usable).
Example query:
SELECT * FROM CustomerAccount WHERE SUBSTRING(AccountNbr, 0, CHARINDEX('-', AccountNbr)) = '999999'
This query is searching for an account number where everything up to the hyphen is stripped out. Applying the SUBSTRING function causes a scan and as a result a long execution. While a LIKE wildcard can solve this, I’m doing bad things for examples’ sake. 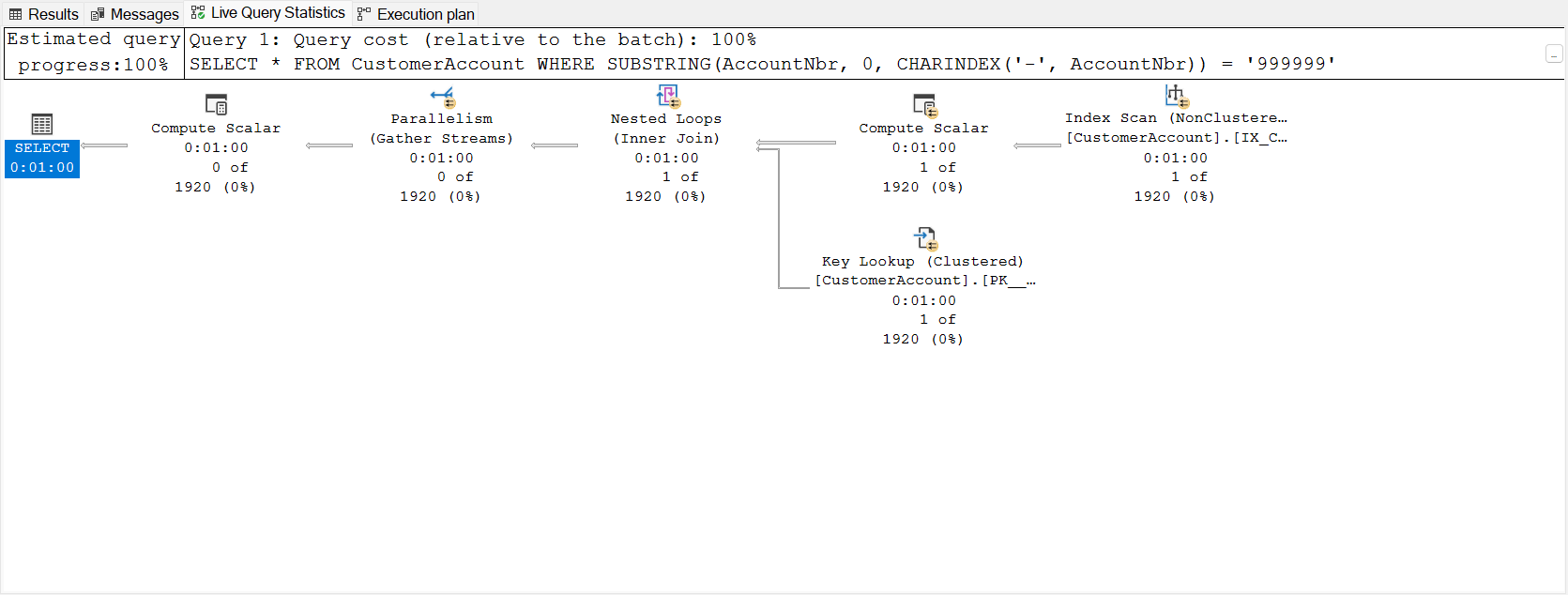
The SUBSTRING causes a large index scan as can be seen above. I killed this query after a minute.
By adding a computed column and indexing it we can get an index seek and improve performance significantly without making any code changes. Indexed computed columns will get picked up without requiring any changes to the query.
The first step to doing this is creating a computed column:
ALTER TABLE CustomerAccount ADD [AccountNbrSubstring] AS (SUBSTRING([AccountNbr],(0),CHARINDEX('-',[AccountNbr])))
Note, we don’t need to mark the computed column as persisted. After adding the computed column, we need to create an index on it. This process can take a while as well as generate blocking as it executes:
CREATE INDEX IX_CustomerAccountSubstring ON CustomerAccount(AccountNbrSubstring)
After creating the index on the computed column, the same query completes in just a few milliseconds. This does not require any application changes for the column to get used against the new column. The optimizer recognizes the predicate (WHERE clause) matches the computed column definition and as a result is able to perform a seek on the index:
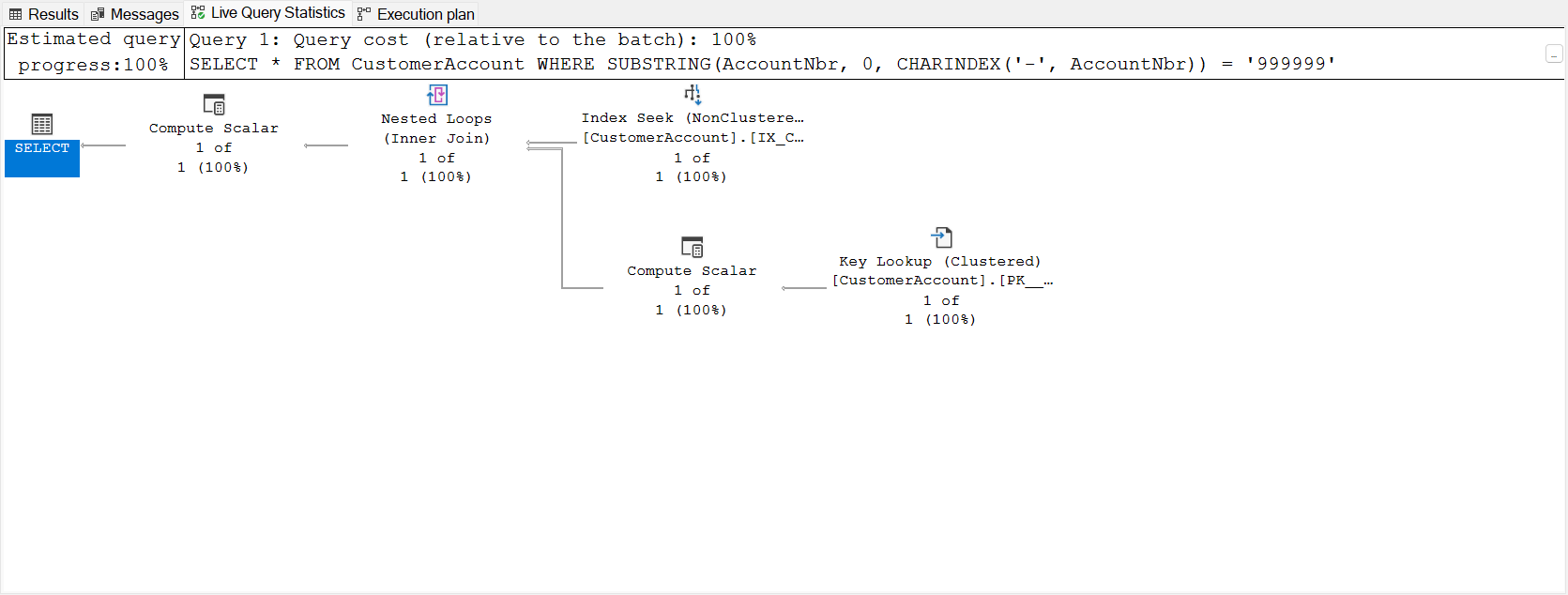
Caveats
Of course, there is additional compute and IO incurred by adding an index. This can be significantly outweighed by the benefits of adding the computed indexed column.