
I’ve seen a lot of discussions and blog posts around tuning max degree of parallelism and cost threshold of parallelism. I’ve read lots of general guidance around decreasing max degree of parallelism (MAXDOP) for servers with greater than 8 CPU’s. From my experience, even when following the guidance on MAXDOP and cost threshold of parallelism settings, SQL Server will occasionally choose plans that get stuck performing parallel operations rather than real work.
In this post I will show you how to determine if a query is potentially spending more time in performing parallel operations than doing real work. The approach we will take to doing this is by monitoring wait events encountered by a query taking a parallel execution plan.
The test query
I was populating some data for the sake of testing when I became curious as to why the query performing the insert was taking so long.
Below is the query I was using:
use adventureworks2012
declare @customerid int
select @customerid = max(customerid) from CustomerTest
INSERT INTO [AdventureWorks2012].[dbo].[CustomerTest]
([CustomerID]
,[PersonID]
,[StoreID]
,[TerritoryID]
,[AccountNumber]
,[rowguid]
,[ModifiedDate])
SELECT row_number() over(order by customerid) + @customerid
,[PersonID]
,[StoreID]
,[TerritoryID]
,[AccountNumber]
,[rowguid]
,getdate()
FROM [AdventureWorks2012].[dbo].[CustomerTest]
As you can see, the query is selecting rows from itself (CustomerTest table) and inserting the same rows back into itself. FYI, if this query looks odd I was doing this to increase the size of the table for some test scenarios.
Investigating the performance
In order to see what the query was doing as it was executing, I queried sys.dm_exec_requests for the session id that was executing it.
select cpu_time, status, wait_type, wait_time, total_elapsed_time,
datediff(ms, start_time, getdate()) as measured_elapsed_time
from sys.dm_exec_requests where session_id = 63
Here’s the results:
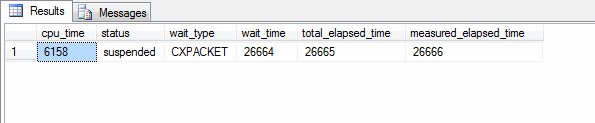
Keep in mind, sys.dm_exec_requests reports what is happening for the current point in time (all times are in milliseconds). You can see that at 26.666 seconds into the query execution we have been in a CXPACKET wait for 26.664 seconds. At the same time, the query has only consumed 6.8 seconds of CPU time.
You can see this in the output from SET STATISTICS TIME ON in this example. At the completion of this query there were 110 seconds of CPU time. There were 148 seconds of elapsed time. This raises the question, what was the query doing for those 38 seconds when it wasn’t using CPU?

The time it takes for a query to respond can typically be measured by:
WAIT TIME + CPU TIME = ELAPSED TIME (approximately)
We are making the assumption that 38 seconds was spent in some sort of wait in this case.
In the above example this equation does not appear to hold true. When querying dm_exec_requests we saw this:
26664(wait time) + 6158(cpu time) > 26666 (measured elapsed time)
The wait_type of CXPACKET gives us a clue as to why. A CXPACKET wait is typically reported during parallel query operations. When this wait is reported, it typically means there are additional tasks performing work in parallel. As a result, a queries’ elapsed time is a factor of the longest running parallel task. Until all parallel tasks are completed, the query will not complete.
Querying sys.dm_exec_requests reports some anomalies that you should be aware of when looking at parallel executions. The cpu_time column is reporting the sum of cpu_time consumed by all parallel tasks spawned by the executing request. The wait_type and wait_time is only reporting waits for the main task (i.e. the parent task).
So the next question is, what are the child parallel tasks doing? We can find that out by looking at sys.dm_os_tasks and sys.dm_os_waiting_tasks.
select t.task_state, t.exec_context_id, wt.wait_type,
wt.wait_duration_ms from sys.dm_os_tasks t
left join sys.dm_os_waiting_tasks wt on t.session_id = wt.session_id
and t.exec_context_id = wt.exec_context_id where t.session_id = 63 and t.exec_context_id > 0
The above query will return rows for the execution request’s child tasks. We filter down to the child tasks by only looking for tasks with an exec_context_id greater than 0.
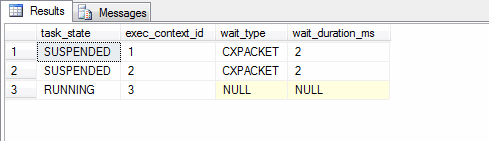
Notice there are 3 child tasks running (indicated by exec_context_id’s 1,2, and 3). One of them is in a running state (i.e. consuming CPU). The other two are waiting. They are in CXPACKET wait (i.e. synchronization wait on parallel operations). It should be noted the wait_duration is only 2 milliseconds; however, running the query repeatedly indicates that the waits continue to occur, just for short intervals. This is something I should have mentioned earlier, but didn’t for the sake of simplicity. The duration of a wait displayed in dm_exec_requests or dm_os_waiting_tasks is not cumulative for the executing request. The duration displayed is only for the wait event occurring at that current point in time. Take for example a query that performs a lot of physical IO. Each time the query performs an IO it will report a wait event. Each wait event might be 10 milliseconds, but the query will generate a 100 of them that contribute to the elapsed time of 1 second. In this case, we see this occurring with CXPACKET waits on the child tasks. These series of short waits result in a longer elapsed time. In SQL 2016 there was the introduction of a new DMV sys.dm_exec_session_wait_stats – this does contain cumulative waits for a session; however, to reach a broader audience I chose not to use it in this post.
Blah blah blah so how does this help me?
If you see that you are not consuming much CPU relative to your measured elapsed time, and most wait events in both sys.dm_exec_requests and sys.dm_os_waiting_tasks are CXPACKET wait, parallelism might not be helping you, in fact it might be slowing you down and consuming more resources in the process.
Let’s make a slight modification to our query to see if this is the case. We’ll add a maxdop 1 hint to force a non-parallel plan:
INSERT INTO [AdventureWorks2012].[dbo].[CustomerTest]
([CustomerID]
,[PersonID]
,[StoreID]
,[TerritoryID]
,[AccountNumber]
,[rowguid]
,[ModifiedDate])
SELECT row_number() over(order by customerid) + @customerid
,[PersonID]
,[StoreID]
,[TerritoryID]
,[AccountNumber]
,[rowguid]
,getdate()
FROM [AdventureWorks2012].[dbo].[CustomerTest] OPTION(MAXDOP 1)
Something I should mention before an observant reader calls me out on it. I was rolling back the inserted rows between my tests in order to have an apples to apples comparison. If I hadn’t done that, it would have skewed my results. That being said, let’s look at the statistics IO output of this query execution when forcing a non parallel plan:

It appears the non-parallel execution had a shorter elapsed time of 128 second compared to the parallel plan taking 148 seconds. The non-parallel plan also used less CPU resources -103 seconds rather than 110 seconds.
In this example I disabled parallelism. If you are testing out performance, you might want to try different degrees of parallelism. Sometimes parallel queries perform better; however, allowing too much parallelism can hurt performance at some point.
What other waits might show up on child tasks?
This goes a little outside the scope of my original topic, but I think it deservers some mention.
Some common waits I see are PAGEIOLATCH* waits, LATCH_EX, PAGELATCH*, and LCK_* waits.
PAGEIOLATCH This will show up if you are doing a lot of physical IO. Some queries that are performing large scans in parallel will generate a lot of PAGEIOLATCH waits. I consider this to be normal given the query isn’t missing an index, the IO subsystem is healthy, and there is a real need to touch a large volume of data.
LATCH_EX This will show up on occasion, if the associated resource is ACCESS_METHODS_DATASET_PARENT, this is a normal wait to see in parallel execution plans. You can see this associated resource in the sys.dm_os_waiting_tasks.resource_description column.
PAGELATCH_* This might be normal but it might not. If you have a large table buffered in memory this might show up during a scan rather than PAGEIOLATCH; however, you should keep an eye out on the resource that the PAGELATCH is on. If it is in tempdb, you should validate that you do not have PFS, GAM, or SGAM wait. In the wait resource you will see will see a wait resource that looks something like “2:1:1”, “2:1:2” or “2:1:3”. There are different variations since there are multiple of these pages in a table, but the main thing to look for is if you are in temp db – the first number in the sequence will be a “2”. If this is the case, you need to research if it is PFS, GAM, or SGAM. If it is, you made need to increase the number of tempdb files you have. You can see the page being contended for in the sys.dm_os_waiting_tasks.resource_description column.
LCK_*, this just indicates your query is running into itself, or into other queries. I have seen where a parallel query was deadlocking on itself.
Conclusion
Parallel query executions can be great when trying to access large datasets where there is no clean way of using indexes; however, it is good to double-check what the parallel tasks are doing and do some testing to see how much the parallel plan benefits you versus doesn’t. I wouldn’t recommend changing your overall system settings over a few queries. I would go with generally followed practices in regards to system MAXDOP settings, but selectively tune queries that don’t behave as expected with MAXDOP hints.
Watch us diagnose a query timeout with SQLGrease:
See how you can get query level wait events without Query Store:
Free you say? How can that be?