
These might be narrow cases I’m describing, but as I’ve seen it happen often enough I figured it is worth writing a post about.
In this post I’ll describe two different scenarios where the DATEDIFF function caused a query to perform poorly due to DATEDIFF not being sargable.
The first scenario I’ll be describing is where queries are written to use DATEDIFF in the predicate (WHERE) to look for date/datetime columns in a relative timeframe (i.e. show me rows modified in the last 30 minutes).
The second scenario I’ll describe is where queries are taking the time difference between two columns to look for rows where a certain amount of time has elapsed between them. A common example of this might be in an order workflow where you might be looking for orders where the time between when an order was taken and when it shipped exceeded a certain duration.
The demo query (first scenario)
The following query is using the DATEDIFF function looking for any records that were modified in the last 30 minutes:
select CustomerID
,NameStyle
,Title
,FirstName
,MiddleName
,LastName
,Suffix
,CompanyName
,SalesPerson
,EmailAddress
,Phone
,PasswordHash
,PasswordSalt
,rowguid
FROM CustomerAccount
WHERE DATEDIFF(MI, GETDATE(), ModifiedDate) > 30
In most cases applying a function to a column prevents an index from being used (there are exceptions). In this case we’re applying the DATEDIFF function to the ModifiedDate column. As a result this is causing it to scan an index on the CustomerAccount table: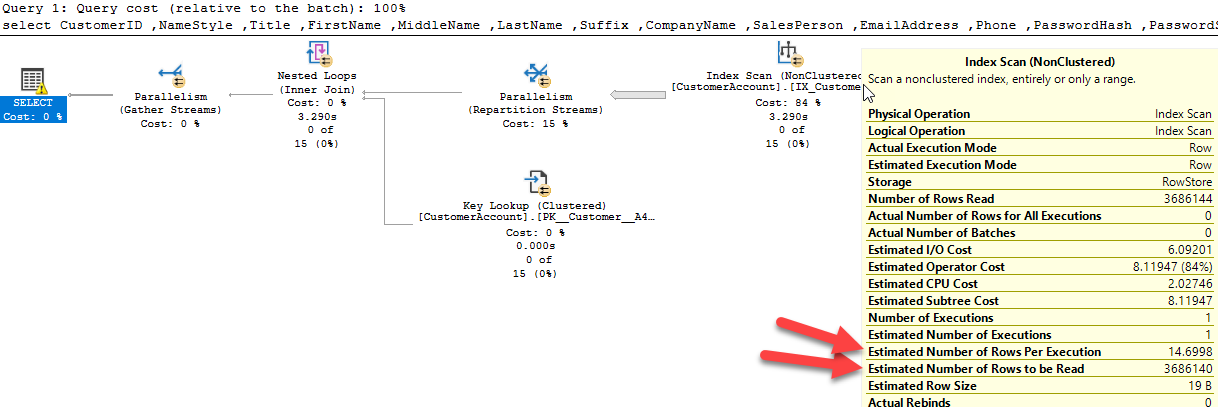
From the plan we could see that this query was estimated to return 14 rows, but it required reading 3.6 million rows in order to do so. This query executed in 5 seconds on average.
Rewritten query
In order to make the WHERE sargable we need to rewrite the query to where we don’t need to apply the DATEDIFF function to the ModifiedDate column. We can accomplish the same goal by calculating 30 minutes ago relative to the current date time. We do this by using DATEADD(mi, -30, get date()).
select CustomerID
,NameStyle
,Title
,FirstName
,MiddleName
,LastName
,Suffix
,CompanyName
,SalesPerson
,EmailAddress
,Phone
,PasswordHash
,PasswordSalt
,rowguid
FROM CustomerAccount
WHERE ModifiedDate > DATEADD(mi, -30, GETDATE())
This query serves the same purpose but is now sargable since it is not applying the DATEDIFF function to an indexed column. As a result this picked up an index on the ModifiedDate:
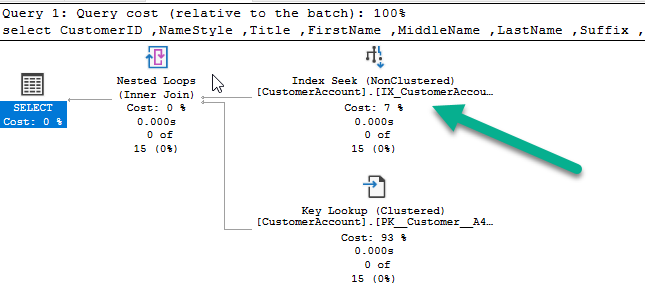
As a result of picking up the index the query now runs in less than 0 milliseconds.
The demo query (scenario 2)
The following query is looking for any rows where a SalesOrderHeader record was created (OrderDate) but it didn’t ship within 10 days (ShipDate):
select * from SalesLT.SalesOrderHeader where DATEDIFF(dd, OrderDate, ShipDate) >= 10
Since DATEDIFF is not sargable this will result in a scan:
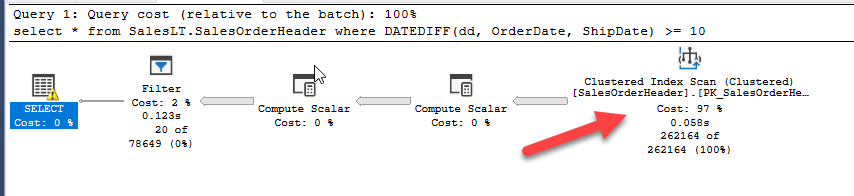
This plan executes in 271 milliseconds.
One option is to create a new column that programmatically gets populated; however, that will require code changes. There is another option that won’t require code or query changes. This option involves creating a computed column on the DATEDIFF between the OrderDate and ShipDate.
By adding this column:
ALTER TABLE SalesLT.SalesOrderHeader ADD OrderToShipDays AS DATEDIFF(dd, OrderDate, ShipDate)
And adding this index to the column:
CREATE INDEX IX_SalesOrderHeader ON SalesLT.SalesOrderHeader(OrderToShipDays)
This is the new execution plan with no changes made to the original query:
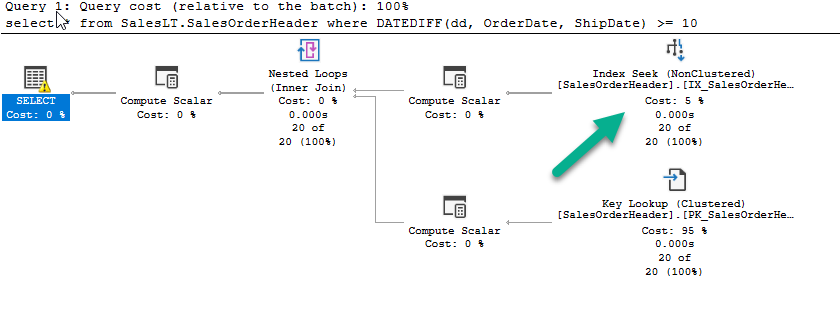
We are now getting an index seek. This new plan executes in 0 milliseconds. Whenever I show someone indexed computed columns I get asked the question multiple times “You didn’t need to change the query to use the new column?” The answer is no. The optimizer recognizes the existence of the indexed computed column and realizes it matches the original query – as a result it’s smart enough to pick it up. One last note on computed columns – not every function can be used in a computed column. The function must be deterministic in order to be used in a computed column. This link from Microsoft describes this in more details.
Final thoughts
Your situation may vary. How frequently a problematic DATEDIFF gets hit and how much pain it causes your organization should be factors in code rewrites or SQL Server features such as computed columns. Sometimes these types of fixes are warranted for critical workload and your organization is just not quick enough to react with code fixes. I wouldn’t apply indexed computed columns everywhere; however, if you’re in a pinch these can really save you.
This is an awesome post. I had never taken into account the sargability of the DATEDIFF function when used in the predicate . My initial assumption when looking at a problematic query is to validate that whatever column is used in the where clause , that it’s indexed or not.
Such a straight forward solution for potential and existing problematic SQL. I am going to use this for some procs that I know use the DD function in the WHERE predicate.